Big Data Jargons
Here we have some big data jargon just to make you look techie again.

Apache™ Hadoop® is an open source software project that enables distributed processing of large data sets across clusters of commodity servers. It is designed to scale up from a single server to thousands of machines, with very high degree of fault tolerance. Rather than relying on high-end hardware, the resiliency of these clusters comes from the software’s ability to detect and handle failures at the application layer.

To know more:
-
http://hortonworks.com/hadoop/
-
http://www-01.ibm.com/software/data/infosphere/hadoop/
-
http://www.tutorialspoint.com/hadoop/
Pig: A Big Data Scripting Language that uses Apache Hadoop. Pig scripts are translated into a series of MapReduce jobs that are run on the Apache Hadoop cluster.
Personal comments: To me it looks like a mix of SQL and Shell Scripting. Not completely unknown to us.
To know more :
- http://hortonworks.com/hadoop-tutorial/how-to-process-data-with-apache-pig/
YARN
YARN is the architectural center of Hadoop that allows multiple data processing engines such as interactive SQL, real-time streaming, data science and batch processing to handle data stored in a single platform, unlocking an entirely new approach to analytics.
HDFS
Since its first deployment at Yahoo in 2006, HDFS has established itself as the defacto scalable, reliable and robust file system for big data. Since then, HDFS has addressed several fundamental challenges of distributed storage at unparalleled scale and with enterprise rigor.
HDFS is a** Java-based file system** that provides scalable and reliable data storage, and it was designed to span large clusters of commodity servers. HDFS has demonstrated production scalability of up to 200 PB of storage and a single cluster of 4500 servers, supporting close to a billion files and blocks. When that quantity and quality of enterprise data is available in HDFS, and YARN enables multiple data access applications to process it, Hadoop users can confidently answer questions that eluded previous data platforms.
SPARK
Spark adds in-Memory Compute for ETL, Machine Learning and Data Science Workloads to Hadoop. With Spark developers everywhere can now create applications to exploit Spark’s power, derive insights, and enrich their data science workloads within a single, shared dataset in Hadoop.
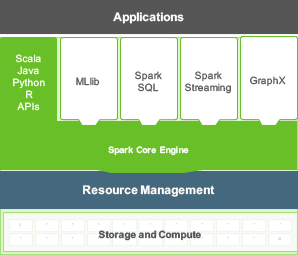
Apache Spark consists of Spark Core and a set of libraries. The core is the distributed execution engine and the Java, Scala, and Python APIs offer a platform for distributed ETL application development
Hive
Hive is built on the Map Reduce framework, Hive is a data warehouse that enables easy data summarization and ad-hoc queries via an SQL-like interface for large datasets stored in HDFS.
To know more - more jargon you might love to pay a visit @ http://hortonworks.com/hadoop/.